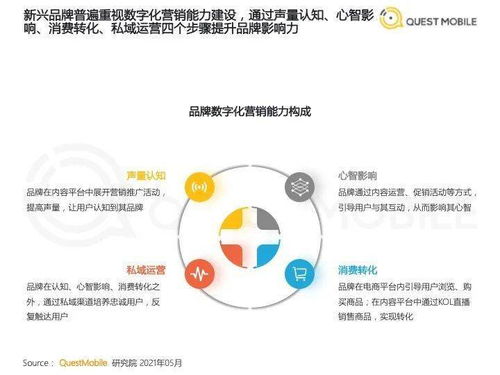
隨著互聯(lián)網(wǎng)上網(wǎng)服務(wù)的普及和數(shù)字技術(shù)的快速發(fā)展,食品飲料行業(yè)在2021年迎來了新品牌數(shù)字化營銷的重要轉(zhuǎn)折點(diǎn)。本報告基于行業(yè)數(shù)據(jù)與案例分析,深入探討了新品牌如何利用數(shù)字化工具實(shí)現(xiàn)市場突破,并總結(jié)了關(guān)鍵洞察與趨勢。
一、數(shù)字化營銷的背景與驅(qū)動因素
2021年,全球疫情加速了消費(fèi)者線上行為的轉(zhuǎn)變,食品飲料行業(yè)新品牌面臨機(jī)遇與挑戰(zhàn)。互聯(lián)網(wǎng)上網(wǎng)服務(wù)的廣泛覆蓋,使得品牌能夠通過社交媒體、電商平臺和移動應(yīng)用等渠道,精準(zhǔn)觸達(dá)目標(biāo)受眾。驅(qū)動因素包括:消費(fèi)者對健康、便捷和個性化產(chǎn)品的需求上升;數(shù)字化基礎(chǔ)設(shè)施的完善,如5G網(wǎng)絡(luò)和智能設(shè)備普及;以及大數(shù)據(jù)和AI技術(shù)的應(yīng)用,賦能營銷決策。
二、新品牌數(shù)字化營銷的主要策略
- 社交媒體營銷:新品牌積極利用抖音、小紅書、微博等平臺,通過KOL合作、短視頻內(nèi)容和用戶互動,建立品牌認(rèn)知度和忠誠度。例如,一些新興飲料品牌通過病毒式視頻傳播,迅速獲得年輕消費(fèi)者青睞。
- 電商渠道整合:依托淘寶、京東、拼多多等平臺,新品牌采用直播帶貨、限時促銷和會員體系,提升轉(zhuǎn)化率。2021年數(shù)據(jù)顯示,食品飲料類目在電商平臺的銷售額同比增長超過30%。
- 數(shù)據(jù)驅(qū)動個性化營銷:通過收集用戶行為數(shù)據(jù),新品牌實(shí)現(xiàn)精準(zhǔn)廣告投放和產(chǎn)品推薦,提高營銷效率。例如,利用AI算法分析消費(fèi)者偏好,推出定制化口味或包裝。
- 內(nèi)容營銷與故事講述:新品牌注重品牌故事的傳播,通過博客、視頻和社區(qū)論壇,分享產(chǎn)品來源、健康理念或可持續(xù)發(fā)展承諾,增強(qiáng)情感連接。
三、關(guān)鍵洞察與挑戰(zhàn)
- 洞察:數(shù)字化營銷降低了新品牌的市場準(zhǔn)入門檻,但競爭加劇。成功品牌往往具備敏捷的響應(yīng)能力和創(chuàng)新能力,能夠快速適應(yīng)市場變化。
- 消費(fèi)者行為變化:2021年,消費(fèi)者更傾向于通過線上渠道獲取信息和購買,對品牌透明度和可持續(xù)性要求提高。新品牌需注重口碑管理和用戶反饋循環(huán)。
- 挑戰(zhàn):數(shù)據(jù)隱私法規(guī)(如GDPR和中國的個人信息保護(hù)法)對營銷策略構(gòu)成約束;同時,流量成本上升和平臺算法變化,要求品牌持續(xù)優(yōu)化投放策略。
四、未來趨勢與建議
食品飲料新品牌的數(shù)字化營銷將更加依賴AI和物聯(lián)網(wǎng)技術(shù),實(shí)現(xiàn)全渠道整合。建議新品牌:加強(qiáng)數(shù)據(jù)安全合規(guī);投資于用戶體驗(yàn)和社區(qū)建設(shè);擁抱新興技術(shù)如AR/VR體驗(yàn)營銷。互聯(lián)網(wǎng)上網(wǎng)服務(wù)的持續(xù)升級將為行業(yè)帶來更多創(chuàng)新機(jī)會。
2021年食品飲料行業(yè)新品牌的數(shù)字化營銷在互聯(lián)網(wǎng)上網(wǎng)服務(wù)的推動下,展現(xiàn)出活力與潛力。品牌應(yīng)持續(xù)學(xué)習(xí)與迭代,以數(shù)據(jù)為驅(qū)動,構(gòu)建可持續(xù)的數(shù)字化生態(tài)。